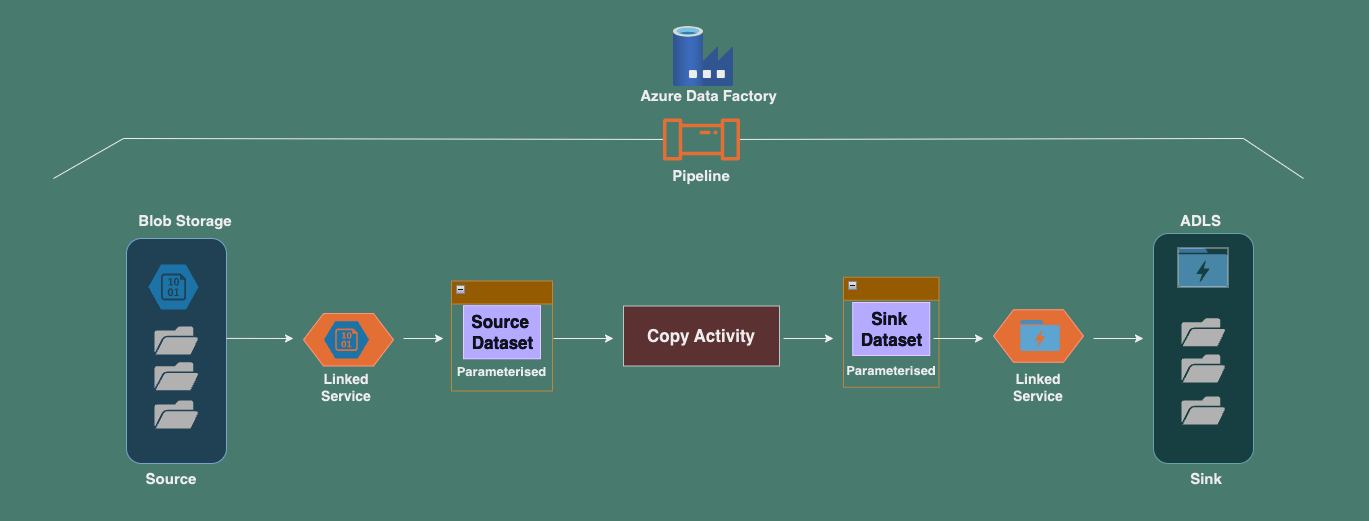
In this post, we’ll explore how to dynamically copy multiple files or folders using parameterized datasets in Azure Data Factory (ADF). This method is ideal for scenarios where you have a set list of files or folders to copy, and you can manually configure or schedule the process with known values. It’s well-suited for static data copying tasks.
Objective:
The goal is to use parameterized datasets to dynamically copy files or folders from an Azure Blob Storage account to an Azure Data Lake Storage (ADLS) account. The parameters allow flexibility in copying multiple files or folders without hardcoding file paths, making your pipeline reusable for various sources and destinations.
Example Scenario:
Let’s say you have several files, such as customer.csv, employee.csv and orders.csv which you want to copy from one location to another. In this case, we can configure parameter values in the pipeline manually or through scheduled triggers to handle the copying process.
Pre-requisites:
To proceed with this hands-on tutorial, ensure that the following are set up:
- Azure Blob Storage account: For storing your source files.
- Azure Data Lake Storage (ADLS) account: Blob storage with hierarchical namespaces enabled for your destination.
- Azure Data Factory (ADF): For creating and managing the pipeline.
- Linked services in ADF: Create two linked services: one for the source (Blob Storage) and one for the sink (ADLS).
Hands-on Steps:
- Complete Pre-requisites: Ensure that all required accounts and linked services (source and sink) are set up and configured properly.
- Create Source Containers:
- Create containers in Blob Storage for your files. For example, create folders like
customer,employee, andordersand upload corresponding.csvfiles into these folders.
- Create containers in Blob Storage for your files. For example, create folders like
- Create Parameterized Dataset for Source:
- In ADF, create a Parameterised Dataset for the Source container (Blob Storage).
- Do not select any specific values for the File path or Filename during the creation of the dataset.
- Go to the Parameters tab, and create a new parameter, e.g.,
ds_param_source_container. - In the Connection tab, for the Container field, click on Add dynamic content and select the parameter
ds_param_source_container. This will dynamically populate the container during runtime using the parameter values.
- Create Parameterised Dataset for Sink:
- Similarly, create a parameterized dataset for the Sink container (ADLS).
- Do not select any specific values for the File path or Filename.
- Go to the Parameters tab, and create a new parameter, e.g.,
ds_param_sink_container. - In the Connection tab, for the Container field, click on Add dynamic content and select
ds_param_sink_containerto populate the container dynamically.
- Create the Pipeline:
- Now, create a pipeline in ADF that includes a Copy Activity.
- Configure the pipeline to dynamically copy files between source and sink containers by passing parameter values to the datasets during pipeline execution.
- Debug the Pipeline:
- After setting up the pipeline, use the Debug feature in ADF to test the pipeline and verify the file copying process.
Key Pipeline Settings for the 1st Pipeline Run:
- Copy Activity – Source Settings:
- Dataset properties:
ds_param_source_container = employee - Wildcard paths:
*(to copy all files in the folder)
- Dataset properties:
- Copy Activity – Sink Settings:
- Dataset properties:
ds_param_sink_container = empout
- Dataset properties:
Key Pipeline Settings for the 2nd Pipeline Run:
- Copy Activity – Source Settings:
- Dataset properties:
ds_param_source_container = orders - Wildcard paths:
*(to copy all files in the folder)
- Dataset properties:
- Copy Activity – Sink Settings:
- Dataset properties:
ds_param_sink_container = ordersout
- Dataset properties:
Running the Pipeline for Multiple Files:
To copy different files in subsequent pipeline runs, simply change the source and sink container folder names in the parameter settings. For example, for the third pipeline run, you can update the source to customers and the sink to custout in the parameterised datasets.
Conclusion:
Using parameterised datasets in Azure Data Factory provides a flexible way to copy files or folders dynamically between Azure Blob Storage and ADLS. By leveraging parameters, you can make your pipelines reusable and adaptable to different datasets without hardcoding values. This is particularly useful for static scenarios where the list of files or folders is known beforehand.